
We introduce Correspondence-Oriented Imitation Learning (COIL), a conditional policy learning framework for visuomotor control with a flexible task representation in 3D. At the core of our approach, each task is defined by the intended motion of keypoints selected on objects in the scene. Instead of assuming a fixed number of keypoints or uniformly spaced time intervals, COIL supports task specifications with variable spatial and temporal granularity, adapting to different user intents and task requirements. To robustly ground this correspondence-oriented task representation into actions, we design a conditional policy with a spatio-temporal attention mechanism that effectively fuses information across multiple input modalities. The policy is trained via a scalable self-supervised pipeline using demonstrations collected in simulation, with correspondence labels automatically generated in hindsight. COIL generalizes across tasks, objects, and motion patterns, achieving superior performance compared to prior methods on real-world manipulation tasks under both sparse and dense specifications.

Extending object-centric flow formulations, our task representation describes the desired changes of the environment state using a collection of K keypoints selected on the scene objects, spanning across H discrete time steps. By allowing varying number of keypoints and time steps, we achieve the following flexibilities:
COIL introduces the Spatio-temporal Transformer architecture to effectively ground sparse spatial correspondence representations into visual observations and robot actions, which interleaves self-attention layers in both spatial and temporal dimensions with cross-attention layers that fuse information from the pointcloud observations.
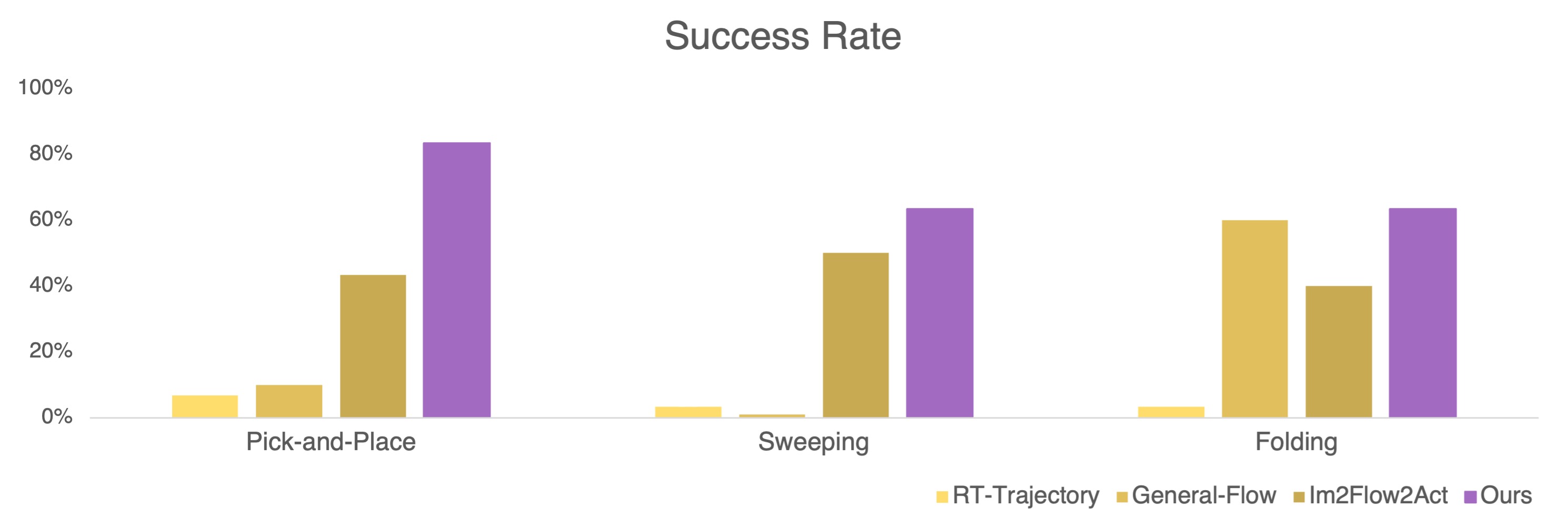
We evaluate COIL on a variety of manipulation tasks with out-of-distribution object shapes and appearances, and compare with prior state-of-the-art methods on three granularity settings of Spatial Correspondence - Sparse(3-5 key points, 2-5 steps), Medium (8-12 key points, 16 steps), and Dense (32 key points, 32 steps). COIL consistently outperforms prior methods across all tasks and settings, demonstrating its effectiveness and generalization ability.
Given both sparse and dense task specifications, COIL is able to generalize to a variety of manipulation tasks with novel object appearances and shapes. Below are some example tasks that COIL can perform.
We further demonstrate the flexibility of COIL by performing tasks with both sparse and dense specifications on a pick-place-avoidance task and a wiping task.
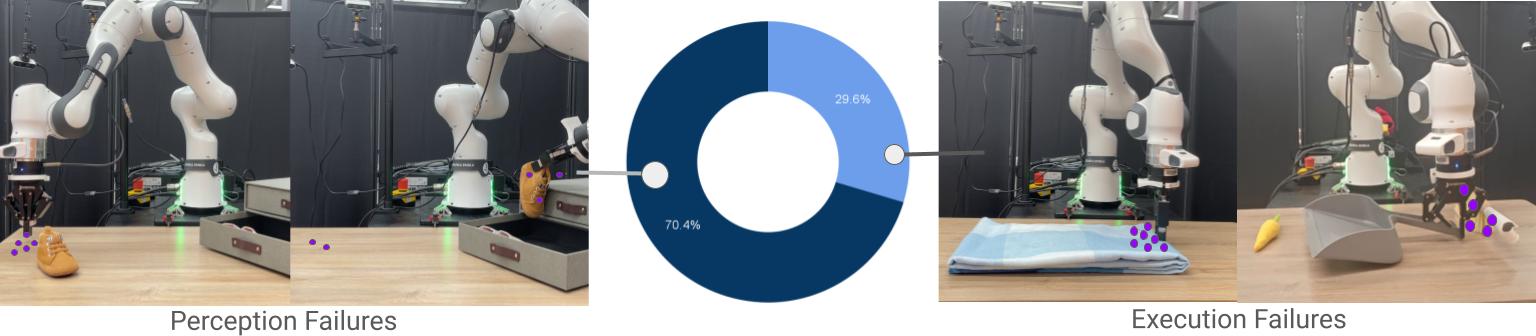
We categorize real-world failure cases into perception failures and execution failures, and visualize their proportions across all evaluation tasks. The majority of failures stem from inaccuracies in point tracking, particularly under occlusion or clutter. Execution failures most commonly occur during the grasping phase , often when objects are flat or lack distinctive geometry, making it difficult for the policy to localize reliable grasp points.
In this example, the key points on the shoe moved too rapidly when brought close to the container, causing tracking failures and the policy to output actions that hit the shoe on the container surface.
In this example, the policy failed to predict accurate grasping and placing actions for executing the tasks.
@misc{coil2025,
title={Correspondence-Oriented Imitation Learning: Flexible Visuomotor Control with 3D Conditioning},
author={Yunhao Cao and Zubin Bhaumik and Jessie Jia and Xingyi He and Kuan Fang},
year={2025},
eprint={2512.05953},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2512.05953},
}